下层TaskScheduler的逻辑:
am role支持 :
每个角色有不同的component用途,比如启动regionserver,启动storm
每个excutor用途只是每个stage有关,stage和执行的sqlplan有关,或者是rdd flunce有关
DAG与task的使用
DAG(directed acyclic graph )
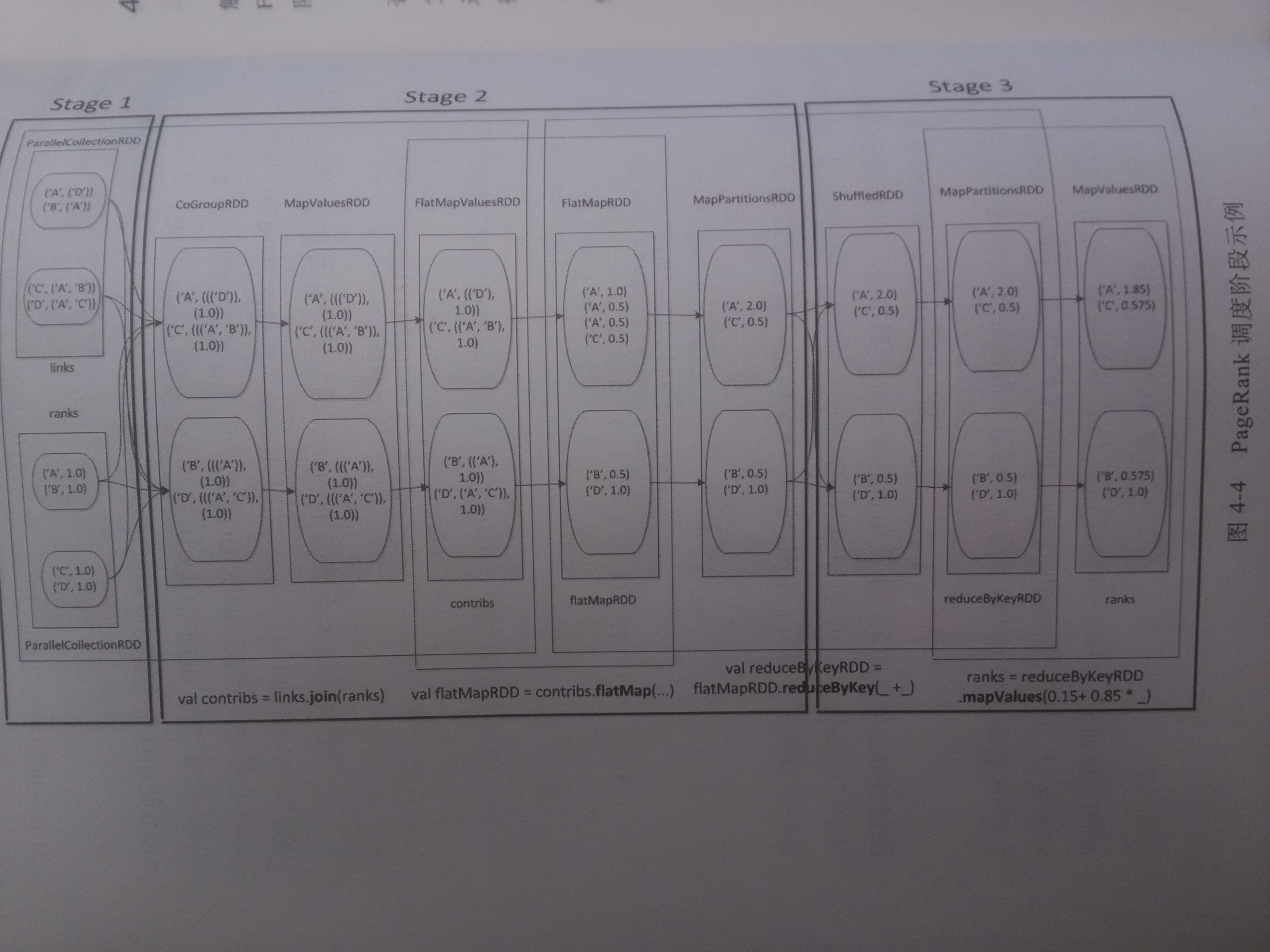
调度
- 任务因果关系
- 没有循环
DAG实现:
- TASK TASKSET STAGE JOB(RDD Action) APP
- DAGScheduler是TaskScheduler的上层抽象调度。
- code隐式提交JOB
- DAG:因果图,返回和输出触发做计算。
- submitJob异步, runJob同步
- sparkContext-dagscheduler
- 事件循环逻辑:akka actor
- ’状态机‘ DAGSchedulerEvent- (hadndler.hadndler)DAGShedulerEventProcssActor.receive()
因果图:
- jod-stage
- stage-jobs
- stage-stage
- shuffle-mapstage
- job-Activejob
- resultstage-job
- stage-infos
- waitingstages
- rynningstages
- failedstages
- pendingtasks
计算:
拆分逻辑:上层抽象rdd成下层的stage:
- 从最终目标的RDD向前检查shuffleDependency,遇到宽依赖(shuffleDependency groupby join),则创建一个Stage,直至读到最初的RDD,stage-stage.
- 当检查的rdd依赖关系为shuffle,将父rdd和shuffleDependency作为一个stage,输出分区结果由partitioner决定。
- shufflerdd本身从父rdd开始,输出参考shufflerDependency,获取shuffle结果从下个stage进行
提交逻辑:shuffleMapTask->finalstage.submitTasks(TaskSet)
- DAGscheduler:finalStage-job
- 检查父调度结果-尝试提交不可用,放入等待队列(shuffleMapTask和事件循环结束)
- finalstage.submitTasks(TaskSet)-> TaskSetManager1-1taskSet
获取逻辑:ShuffleMapTask ResultTask
ShuffleMapTask 中间结果的task
- mapstatus ->blockmanager
resultTask finalstage对应的任务最重结果
- DirectTaslResult
- InDirectTaskResult 大于10m序列化
DAGScheduler->TaskSetManager使用TaskScheduler
am delayed队列线程池
支持操作和异步动作放入队列等待操作,顺序操作调度
fiarpool和fifopool,采取了和FairScheduler一样的调度?am anti-annatiy
把相同compoenent类型可以分离开喜好关联,放到不同的机器上
全是excutor不用考虑,把此类excutor放到不同机器上,没有喜好问题 ? http://jayfans3.github.io/2015/04/sparkSchedulerVSslider
TaskSetManager1-1taskset
- resourceOffer :Locality:PROCESS_LOCAL,NODE_LOCAL,NO_PREF,RACK_LOCAL,ANY
- spark.locality.wait.process/node/rack 3000ms
- handleSuccessfuleTask/handleFailedTask/handleTaskGettingResult
- speculation 推测重复调度某个taskset
池采用了调度池非队列管理TaskSetManager,非服务操作。
- fifo:管理tasksetmanagerh
- fair:管理下一级调度池或者tasksetmanager,minshare weight
- 限于app 调度池,app-job-stage-tastset 不是整个yarn中的app的调度池
- 常驻yarn-client的sparkContext算一个app,代理了多个server连接的app的job
本地性
长时服务和短时服务,在初次申请container时候,没有数据本地性信息,之后才能使用池来调度任务操作服务。
本地性
- hdfs
- 第一层资源分配时候executor没有数据本地性,申请下来的container每台机器上都有executor还好,否则没有数据本地性,yarn可传local位置。其他的workermaster没有这功能。。。